RecordReaders
Record Readers : How records are honored in HDFS
Lets start with having a quick understanding of a file saved in Linux OS
1. vim /etc/fstab to know the filesystem of the disk.
2. create and save a file using vim.
3. filefrag -v filename
Facts to appreciate.
1. Filefrag commands will give you an idea of how many blocks( OS blocks formed by grouping sectors) the file occupies. block is the minimum data that can be read by the OS . Data is fetched from hard disk in multiples of the blocks.
2. The blocks might not be contiguous( can you corelate something to HDFS).
3. The filesystem has no idea about a record saved in the file or the format of the file. For the filesystem file is a sequence of bytes.
4. Number of blocks occupied on Linux FileSystem is filesize/filesystem block size , which mostly is file size/ 4096 for ext3/4.
5. Record is a logical entity which, only the reader and writer of the file and can understand. Filesystem has no clue about the same.
6. We have standardized the process of identifying a record with file format.
7. Example In a file of “text” format record is the sequence of byte contained within two \n.
8. The editors we use have this logic inbuilt in them example vim is a text editor, which has this notion of \n determining records, which is part of its code base.
9. A record can be spread across two blocks, as while dividing the file into blocks, filesystem dosent consider anything about the notion of records.
[addToAppearHere]
The file in the hadoop world.
When a file is stored in hadoop filesystem which is distributed in nature, following facts need to be appreciated.
1. HDFS is distributed in nature.
2. HDFS uses the OS file system on the individual nodes to store data. On individual node a HDFS blocks, is saved as multiple OS blocks on hard disk. HDFS blocks in itself is a higher level abstraction. One hdfs block (148 MB) on a given node comprises of multiple OS blocks(4K bytes) which is made of sectors(512 bytes) on the hard-disk.
3. The file is divided into HDFS blocks by: Num blocks = fileSize/ Hadoop block size.
4. The File blocks might reside on the same node or distributed across multiple nodes.
5. The HDFS has no idea of the notion of record or file format. For HDFS file is just a sequence of bytes that needs to be stored.
6. As there is no notion of records, it is very much possible that a record is split across two blocks.
7. To view the blocks of a file in HDFS use hadoop fsck filePath -file -blocks.
[addToAppearHere]
The Question arises who takes care of honoring the notion of records and file formats on hadoop.
1. InputFormats.
2. RecordReaders.
InputFormat is the code which knows how to read a specific file, hence this is the code which helps you reading a specific file format. Just like we use vim to open text files, adobe to open pdf format files, similary we use TextInputformat to read text files saved on HDFS, SequenceFileInput Format to read sequence files in hadoop. InputFormat holds the logic of how the file has been split and saved, and which recordreader will be used to read the record in the splits.
Once we have the InputFormats the next logical question is which component decides how the sequence of bytes read to be converted into records. RecordReader is the code which understands how to logically form a record from the stream of read bytes.
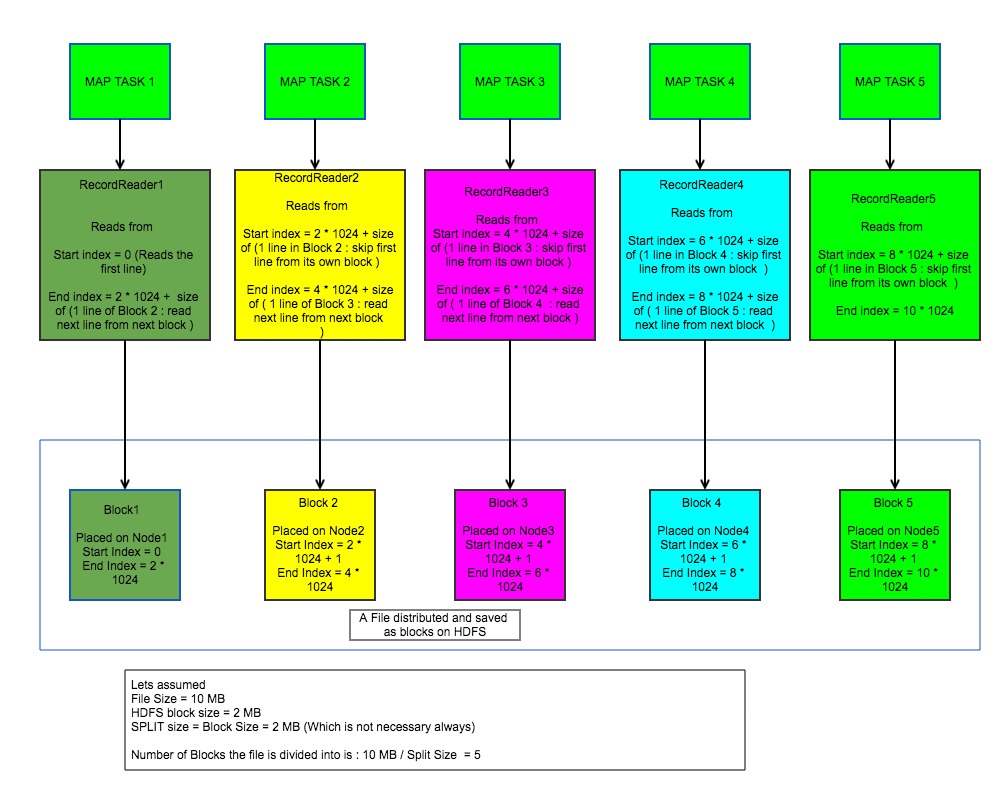
Lets take example of a Text file and try to understand the concepts in-depth. Let there be a text file, the format itself says a record is formed by all the bytes between \n or \r, and the individual bytes in the record will be encoded in UTF-8. Lets assume a big text file is saved onto HDFS.
The facts to understand is.
1. The file is broken into HDFS blocks and saved. The blocks can be spread across multiple nodes.
2. A record can be split between two hdfs blocks.
3. Text Input format : uses LinerecordReader
4. TextInputFormat uses the logic of fileSize/ HDFS blocksize ( getSplit Functionality ) to find the number of blocks the file consists of.
5. For each file block one can find the start byte and end byte index which is provided as the input to the record reader.
6. A record reader knows to read from byte index X to Byte index Y with certain conditions
1. If starting byte index X == 0 (starting of the file ) then include all the bytes till \n in the first record.
2. If the starting byte index X != 0 (All the blocks except the first block) then leave the byte till the first \n is encountered.
3. IF byte index Y = file size ( End of File) then do not read any further records.
4. if byte index Y != file size (The blocks excluding the last block) then go ahead and read extra record from the next block.
What all the condition ensures is.
1. The recordreader which reads the first block of file consumes the first line.
2. All other record reader always skip the initial bytes till the first \n occurs.
3. The last blocks record reader only reads till the last line.
4. Except the last block rest of the block record readers read the last line and first line of the subsequent block