How HiveServer2 Apply Ranger Policies
How HiveServer2 Apply Ranger Policies
Apache Ranger.
Apache Ranger™ is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform. The vision with Ranger is to provide comprehensive security across the Apache Hadoop ecosystem. With the advent of Apache YARN, the Hadoop platform can now support a true data lake architecture. Enterprises can potentially run multiple workloads, in a multi tenant environment. Data security within Hadoop needs to evolve to support multiple use cases for data access, while also providing a framework for central administration of security policies and monitoring of user access.
Ranger Goals Overview
Apache Ranger has the following goals:
- Centralized security administration to manage all security related tasks in a central UI or using REST APIs.
- Fine grained authorization to do a specific action and/or operation with Hadoop component/tool and managed through a central administration tool
- Standardize authorization method across all Hadoop components.
- Enhanced support for different authorization methods – Role based access control, attribute based access control etc.
- Centralize auditing of user access and administrative actions (security related) within all the components of Hadoop.
Ranger maintains various type of rule mapping the general layout looks like
1. User -> groups -> policy -> actual Resource(hdfs, hive tables) access/deny/allowed/read/write
2. User -> policy -> actual Resource(hdfs, hive tables) access/deny/allowed/read/write
Key Take away of Ranger
1. Ranger is not an Identity management system, its a service which hold the policy mappings 2. Ranger is least worried about the user name and group names actual relation. 3. You can create a dummy group and attach it to a user, ranger is not bothered if this relationship exsist in LDAP or not 4. Ranger users and groups are snynced from the same LDAP which powers the rest of Hadoop cluster. 5. Its is the common ldap shared between Ranger and Hadoop cluster which enables them to see the same user. 6. No where Ranger claims that it knows all the user present on the cluster, its the job of Ranger user to sync users and groups to Ranger.
[addToAppearHere]
How HiveServer2 and Ranger Interacts
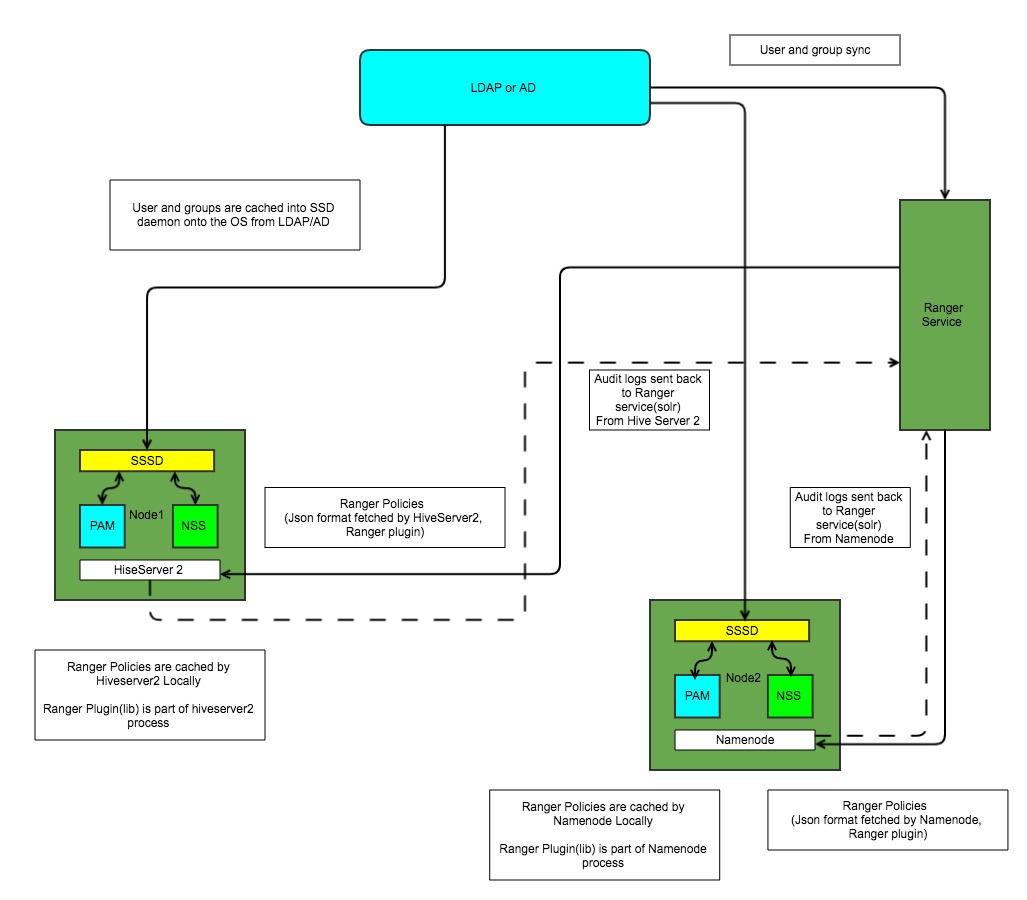
How it all works (doAs=true impersonation enabled).
1. Ranger policies are fetched by HiseServer2 and maintained in local cache. Do realize hive ranger plugin is not a separate process, but a lib which is executed along with HivseServer2.
2. User Authenticates to Hiveserver2 using one of the specified authenticating mechanism LDAP, Kerberos, PAM etc
3. HiveServer2 gets the username during the authentication phase. Do remember even with Kerberos Authentication groups available in the ticket are never used.
4. Based on how core-site.xml if configured hivserver2 either lookups LDAP to fetch groups of the authenticated user OR it does a lookup from the underlying OS (NSS -> SSSD -> LDAP) to fetch the groups.
5. Once groups are fetched, Hiverser2 has mapping of user to groups of authenticated user.
6. HiveServer2 Ranger plugin has mapping of user -> groups -> policy, now the groups which were fetched from hiveserver2 are used to select the ranger policy and enforce them.
7. Just realize ranger might provide a relation of user 1 -> mapper to 3 groups -> 3 groups mapped to 3 policies. Not all the policies, mapped to the three groups will be applied by default.
8. Hiveserver2 will fetch the groups at its own end (LDAP or through OS) and only the overlapping groups with the ranger groups rules will be used while enforcing the policies.
9. Hiveserver2 (ranger plugin lib) will write audit logs locally which is eventually pushed to ranger service (solr).
10. If due to some reason groups are not fetched from HiveServer2 for the authenticated user all the Ranger policies mapped to those groups will not be applied.
11. Sometime mapping user to policies directly help mitigating issues in case LDAP is not working correctly.
12. Do realize all the mapping here are in terms of group names and not gid. As there can be scenario that gid is available on the OS but no groups.
Config
Hiveserver2-site. hive.security.authorization.manager. org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory RangerHiveAuthorizerFactory => calls RangerHiveAuthorizer => which internally calls a checkPrivileges() method , which subsequently gets groups of the authenticated user using UserGroupInformation class.
[addToAppearHere]
Code Flow :
Ranger Authorization
https://github.com/apache/ranger/blob/master/hive-agent/src/main/java/org/apache/ranger/authorization/hive/authorizer/RangerHiveAuthorizerFactory.java
checkPrivileges : from userName get groups and check prividigles.
UserGroupInformation ugi = getCurrentUserGroupInfo();
Get Groups from Username.
Set<String> groups = Sets.newHashSet(ugi.getGroupNames());
UserGroupInformation mUgi = userName == null ? null : UserGroupInformation.createRemoteUser(userName);
https://github.com/apache/ranger/blob/master/hive-agent/src/main/java/org/apache/ranger/authorization/hive/authorizer/RangerHiveAuthorizerBase.java#L65
getCurrentUserGroupInfo()
https://github.com/apache/ranger/blob/master/hive-agent/src/main/java/org/apache/ranger/authorization/hive/authorizer/RangerHiveAuthorizerBase.java#L92
UserGroupInformation : Core class to authenticate the users and get groups (Kerberos authentication, LDAP, PAM) .
Get groups from User.
http://grepcode.com/file/repo1.maven.org/maven2/com.ning/metrics.action/0.2.0/org/apache/hadoop/security/UserGroupInformation.java#221
Groups : if nothing is mentioned in core-site.xml then call invoke a shell and get groups for the use.
http://grepcode.com/file/repo1.maven.org/maven2/org.apache.hadoop/hadoop-common/2.7.0/org/apache/hadoop/security/Groups.java#Groups.getUserToGroupsMappingService%28org.apache.hadoop.conf.Configuration%29
ShellBasedUnixGroupsMapping: default Implementation
http://grepcode.com/file/repo1.maven.org/maven2/org.apache.hadoop/hadoop-common/2.7.0/org/apache/hadoop/security/ShellBasedUnixGroupsMapping.java#ShellBasedUnixGroupsMapping