Read from Aerospike from Spark via MapPartitions
Read from Aerospike with a spark application via mapPartitions in Spark
Problem Statement : We have keys saved in file present on HDFS and for the given keys one has to lookup values from Aerospike , and save it back on HDFS.
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.0-cdh5.9.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.0-cdh5.9.0</version> </dependency> <dependency> <groupId>com.big.data</groupId> <artifactId>avro-schema</artifactId> <version>${project.version}</version> </dependency> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-avro_2.10</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>com.twitter</groupId> <artifactId>parquet-avro</artifactId> <version>1.5.0-cdh5.9.0</version> </dependency> <dependency> <groupId>com.googlecode.json-simple</groupId> <artifactId>json-simple</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-csv_2.10</artifactId> <version>1.5.0</version> <scope>compile</scope> </dependency> <dependency> <groupId>com.aerospike</groupId> <artifactId>aerospike-client</artifactId> <version>3.2.2</version> </dependency> <dependency> <groupId>com.aerospike.unit</groupId> <artifactId>aerospike-unit</artifactId> <version>1.0.0-SNAPSHOT</version> </dependency> </dependencies> [addToAppearHere]
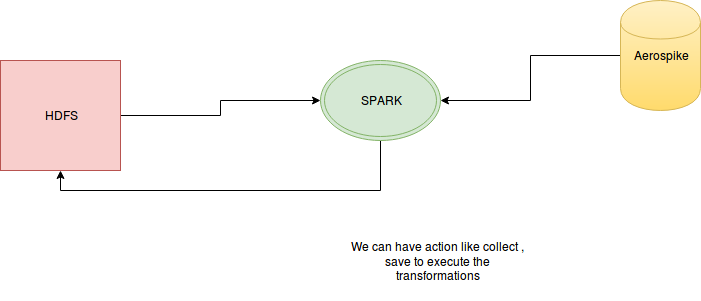
Code :
package com.big.data.spark;
import com.aerospike.client.AerospikeClient;
import com.aerospike.client.Key;
import com.aerospike.client.Record;
import com.aerospike.client.policy.WritePolicy;
import com.big.data.avro.schema.Employee;
import com.databricks.spark.avro.SchemaConverters;
import org.apache.avro.Schema;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.io.Closeable;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import static org.apache.spark.sql.types.DataTypes.StringType;
public class ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition
extends Configured implements Tool, Closeable {
public static final String INPUT_PATH = "spark.input.path";
public static final String OUTPUT_PATH = "spark.output.path";
public static final String IS_RUN_LOCALLY = "spark.is.run.local";
public static final String DEFAULT_FS = "spark.default.fs";
public static final String NUM_PARTITIONS = "spark.num.partitions";
//Aerospike related properties
public static final String AEROSPIKE_HOSTNAME = "aerospike.host.name";
public static final String AEROSPIKE_PORT = "aerospike.port";
public static final String AEROSPIKE_NAMESPACE = "aerospike.name.space";
public static final String AEROSPIKE_SETNAME = "aerospike.set.name";
// For Dem key is emp_id and value is emp_name
public static final String KEY_NAME = "avro.key.name";
public static final String VALUE_NAME = "avro.value.name";
public static final String EMPLOYEE_COUNTRY_KEY_NAME = "emp_country";
private SQLContext sqlContext;
private JavaSparkContext javaSparkContext;
protected <T> JavaSparkContext getJavaSparkContext(final boolean isRunLocal,
final String defaultFs,
final Class<T> tClass) {
final SparkConf sparkConf = new SparkConf()
//Set spark conf here ,
//after one gets spark context you can set hadoop configuration for InputFormats
.setAppName(tClass.getSimpleName())
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
if (isRunLocal) {
sparkConf.setMaster("local[*]");
}
final JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
if (defaultFs != null) {
sparkContext.hadoopConfiguration().set("fs.defaultFS", defaultFs);
}
return sparkContext;
}
@Override
public int run(String[] args) throws Exception {
//The arguments passed has been split into Key value by ToolRunner
Configuration conf = getConf();
String inputPath = conf.get(INPUT_PATH);
String outputPath = conf.get(OUTPUT_PATH);
String aerospikeHostname = conf.get(AEROSPIKE_HOSTNAME);
int aerospikePort = conf.getInt(AEROSPIKE_PORT, 3000);
String namespace = conf.get(AEROSPIKE_NAMESPACE);
String setName = conf.get(AEROSPIKE_SETNAME);
String valueName = conf.get(VALUE_NAME);
//Get spark context, This is the central context ,
//which can be wrapped in Any Other context
javaSparkContext = getJavaSparkContext(conf.getBoolean(IS_RUN_LOCALLY, Boolean.FALSE),
conf.get(DEFAULT_FS), this.getClass());
sqlContext = new SQLContext(javaSparkContext);
// No input path has been read, no job has not been started yet .
//To set any configuration use javaSparkContext.hadoopConfiguration().set(Key,value);
// To set any custom inputformat use javaSparkContext.newAPIHadoopFile() and get a RDD
// Avro schema to StructType conversion
final StructType outPutSchemaStructType = (StructType) SchemaConverters
.toSqlType(Employee.getClassSchema())
.dataType();
final StructType inputSchema = new StructType(new StructField[]
{new StructField("emp_id", StringType, false, Metadata.empty())});
// read data from parquetfile,
// the schema of the data is taken from the avro schema
DataFrame inputDf = sqlContext.read().schema(inputSchema).text(inputPath);
// convert DataFrame into JavaRDD
// the rows read from the parquetfile is converted into a Row object .
// Row has same schema as that of the parquet file roe
JavaRDD<Row> rowJavaRDD = inputDf.javaRDD();
// Data read from parquet has same schema as that of avro (Empoyee Avro).
// Key is employeeId and value is EmployeeName
// In the map there is no special function to initialize or shutdown the Aerospike client.
JavaRDD<Row> returnedRowJavaRDD = rowJavaRDD.mapPartitions
(new InsertIntoAerospike(aerospikeHostname, aerospikePort, namespace,
setName,"emp_id", valueName));
//Map is just a transformation in Spark hence a action
// like write(), collect() is needed to carry out the action.
// Remeber spark does Lazy evaluation, without a action transformations will not execute.
DataFrame outputDf = sqlContext.createDataFrame(returnedRowJavaRDD, outPutSchemaStructType);
// Convert JavaRDD to dataframe and save into parquet file
outputDf
.write()
.format(Employee.class.getCanonicalName())
.parquet(outputPath);
return 0;
}
// Do remember all the lambda function are instantiated on driver, serialized and sent to driver.
// No need to initialize the Service(Aerospike , Hbase on driver ) hence making it transiet
// In the call() , for each record insert into Aerospike , this can be coverted into batch too
public static class InsertIntoAerospike
implements FlatMapFunction<Iterator<Row>, Row> {
// not making it static , as it will not be serialized and sent to executors
private final String aerospikeHostName;
private final int aerospikePortNo;
private final String aerospikeNamespace;
private final String aerospikeSetName;
private final String keyColumnName;
private final String valueColumnName;
// The Aerospike client is not serializable
// and neither there is a need to instatiate on driver
private transient AerospikeClient client;
private transient WritePolicy policy;
public InsertIntoAerospike(String hostName, int portNo, String nameSpace, String setName,
String keyColumnName, String valueColumnName) {
this.aerospikeHostName = hostName;
this.aerospikePortNo = portNo;
this.aerospikeNamespace = nameSpace;
this.aerospikeSetName = setName;
this.keyColumnName = keyColumnName;
this.valueColumnName = valueColumnName;
}
@Override
public Iterable<Row> call(Iterator<Row> rowIterator) throws Exception {
// rowIterator points to the whole partition
// (all the records in the partition) , not a single record.
// The partition can be of Map Task or Reduce Task
// This is where you initialize your service ,
// mapPartition resemble setup , map , cleanup of MapReduce,
// Drawback of mapPartition is it returns after,
// processing the whole chunk not after every row.
// This will be held in memory till whole partition is evaluated
List<Row> rowList = new ArrayList<>();
//This is the place where you initialise your service
policy = new WritePolicy();
client = new AerospikeClient(aerospikeHostName, aerospikePortNo);
// All the code before iterating over rowIterator will be executed only once
// as the call() is called only once for each partition
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
String empID = (String) row.get(row.fieldIndex(keyColumnName));
// As rows have schema with fieldName and Values being part of the Row
Key key = new Key(aerospikeNamespace, aerospikeSetName, Integer.parseInt(empID));
//Get from Aerospike for a given employee id the employeeName
Record result1 = client.get(policy, key);
Employee employee = new Employee();
employee.setEmpId(Integer.valueOf(empID));
employee.setEmpName(result1.getValue(valueColumnName).toString());
// This by default is available for Every key present in Aerospike
employee.setEmpCountry(result1.getValue(EMPLOYEE_COUNTRY_KEY_NAME).toString());
// creation of Employee object could have been skipped its just to make things clear
// Convert Employee Avro To Object[]
Object[] outputArray = new Object[Employee.getClassSchema().getFields().size()];
for (Schema.Field field : Employee.getClassSchema().getFields()) {
outputArray[field.pos()] = employee.get(field.pos());
}
rowList.add(RowFactory.create(outputArray));
}
//Shutdown the service gracefully as this is called only once for the whole partition
IOUtils.closeQuietly(client);
return rowList;
}
}
@Override
public void close() throws IOException {
IOUtils.closeQuietly(javaSparkContext);
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition(), args);
}
}
[addToAppearHere]
Aerospike Unit Test framework:
package com.big.data.spark;
import com.aerospike.client.AerospikeClient;
import com.aerospike.client.Bin;
import com.aerospike.client.Key;
import com.aerospike.client.policy.WritePolicy;
import com.aerospike.unit.impls.AerospikeRunTimeConfig;
import com.aerospike.unit.impls.AerospikeSingleNodeCluster;
import com.aerospike.unit.utils.AerospikeUtils;
import com.big.data.avro.AvroUtils;
import com.big.data.avro.schema.Employee;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import parquet.avro.AvroParquetReader;
import parquet.hadoop.ParquetReader;
import java.io.File;
public class ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartitionTest {
private static final Logger LOG = LoggerFactory.getLogger(ReadWriteAvroParquetFilesTest.class);
private static final String BASEDIR =
"/tmp/ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartitionTest/avroparquetInputFile/"
+ System.currentTimeMillis()+ "/";
private String input;
private String output;
private AerospikeSingleNodeCluster cluster;
private AerospikeRunTimeConfig runtimConfig;
private AerospikeClient client;
//Aerospike unit related Params
private String memorySize = "64M";
private String setName = "BIGTABLE";
private String binName = "BIGBIN";
private String nameSpace = "RandomNameSpace";
@Before
public void setUp() throws Exception {
input = BASEDIR + "input/";
output = BASEDIR + "output/";
Configuration conf = new Configuration();
conf.set("fs.default.fs", "file:///");
FileSystem fs = FileSystem.get(conf);
//Writing all the keys in Hdfs , input to the Job
FSDataOutputStream out = fs.create(new Path(input, "part000"));
out.write("1\n".getBytes());
out.write("2\n".getBytes());
//not exsistent key
out.close();
// Start Aerospike MiniCluster
// Instatiate the cluster with NameSpaceName , memory Size.
// One can use the default constructor and retieve nameSpace,
// Memory info from cluster.getRunTimeConfiguration();
cluster = new AerospikeSingleNodeCluster(nameSpace, memorySize);
cluster.start();
// Get the runTime configuration of the cluster
runtimConfig = cluster.getRunTimeConfiguration();
client = new AerospikeClient("127.0.0.1", runtimConfig.getServicePort());
AerospikeUtils.printNodes(client);
// Insert Values in Aerospike for the appropriate keys
//Fetch both the keys from Aerospike
WritePolicy policy = new WritePolicy();
Key key1 = new Key(runtimConfig.getNameSpaceName(), setName, 1);
Bin bin1 = new Bin("emp_name", "Maverick1");
Bin bin2 =
new Bin(ReadKeysFromHdfsgetValuesfromAerospikeSpark.EMPLOYEE_COUNTRY_KEY_NAME, "DE");
client.put(policy, key1, bin1, bin2);
Key key2 = new Key(runtimConfig.getNameSpaceName(), setName, 2);
Bin bin3 = new Bin("emp_name", "Maverick2");
Bin bin4 =
new Bin(ReadKeysFromHdfsgetValuesfromAerospikeSpark.EMPLOYEE_COUNTRY_KEY_NAME, "IND");
client.put(policy, key2, bin3, bin4);
}
@Test
public void testSuccess() throws Exception {
String[] args = new String[]{"-D" + ReadWriteAvroParquetFiles.INPUT_PATH + "=" + input,
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.OUTPUT_PATH + "=" + output,
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.IS_RUN_LOCALLY + "=true",
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.DEFAULT_FS + "=file:///",
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.NUM_PARTITIONS + "=1",
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.AEROSPIKE_NAMESPACE + "="
+ runtimConfig.getNameSpaceName(),
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.AEROSPIKE_HOSTNAME + "=127.0.0.1",
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.AEROSPIKE_PORT + "="
+ runtimConfig.getServicePort(),
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.AEROSPIKE_SETNAME + "=" + setName,
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.KEY_NAME + "=emp_id",
"-D" + ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.VALUE_NAME + "=emp_name"};
ReadKeysFromHdfsgetValuesfromAerospikeSparkMapPartition.main(args);
// Read from HDFS that the key and values are available
ParquetReader<GenericRecord> reader = AvroParquetReader.builder(new Path(output)).build();
//Use .withConf(FS.getConf())
//for reading from a diferent HDFS and not local , by default the fs is local
GenericData.Record event = null;
while ((event = (GenericData.Record) reader.read()) != null) {
Employee outputEvent = AvroUtils.convertByteArraytoAvroPojo
(AvroUtils.convertAvroPOJOtoByteArray(event,
Employee.getClassSchema()), Employee.getClassSchema());
LOG.info("Data read from Sparkoutput is {}", outputEvent.toString());
Assert.assertTrue(outputEvent.getEmpId().equals(1) || outputEvent.getEmpId().equals(2));
Assert.assertTrue(outputEvent.getEmpName().equals("Maverick1") || outputEvent.getEmpName().equals("Maverick2"));
}
reader.close();
}
@After
public void cleanup() throws Exception {
FileUtils.deleteDirectory(new File(BASEDIR));
if (cluster != null) {
// Stop the cluster
cluster.stop(true);
}
if (client != null) {
client.close();
}
}
}